La revista Investigación y Ciencia me atrajo desde muy joven. La veía en la biblioteca de mi barrio, leía algunos artículos y ojeaba la mayoría. Guardo un recuerdo maravilloso de la variedad de temas, la perfección de los dibujos diagramas y fotografías de los artículos.
Espero que a quién guarde un recuerdo similar de esta revista, le sea
útil esta página.
Seguramente, el json de la base de datos contiene errores,
especialmente en la categorización del tema de cada artículo. Si alguién
emprendela tarea de revisarlo o corregir errores, estaré encantado de
subir las mejoras.
Dialnet es la única página donde aparecien indexados los artículos de "Investigación y Ciencia". Se utiliza Selenium y BeautifulSoup para automatizar la extracción de ejemplares desde la web de Dialnet. El script recorre IDs de ejemplares, accede a su página y extrae:
Este es el código:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup
import json
import time
import random
START_ID = # PONER AQUÍ LA PAGINA FINAL A ESCANEAR DE DIALNET
END_ID = # PONER AQUÍ LA PAGINA FINAL A ESCANEAR DE DIALNET
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
results = []
print("⏳ Esperando antes de iniciar para evitar detección...")
time.sleep(random.uniform(10, 20)) # espera inicial larga
for ejemplar_id in range(START_ID, END_ID + 1):
url = f"https://dialnet.unirioja.es/ejemplar/{ejemplar_id}"
print(f"Accediendo a: {url}")
try:
driver.get(url)
time.sleep(random.uniform(8, 14)) # espera a que cargue bien
soup = BeautifulSoup(driver.page_source, "html.parser")
# NUEVA FORMA DE EXTRAER AÑO Y VOLUMEN
year = volume = None
h3 = soup.select_one("div.tituloDeBloque h3")
if h3:
h3_text = h3.get_text(strip=True)
# Por ejemplo: "Año 1990, Número 160"
if "Año" in h3_text and "Número" in h3_text:
try:
year = h3_text.split("Año")[1].split(",")[0].strip()
volume = h3_text.split("Número")[1].strip()
except Exception as e:
print(f"⚠️ Error extrayendo año/volumen en {url}: {e}")
else:
print(f"⚠️ No se encontró el título del bloque en {url}")
# EXTRAER ARTÍCULOS
articulos = soup.find_all("li", class_="articulo")
for art in articulos:
titulo_tag = art.find("p", class_="titulo")
autores_tag = art.find("p", class_="autores")
paginas_tag = art.find("p", class_="localizacion")
titulo = titulo_tag.get_text(strip=True) if titulo_tag else None
autores = autores_tag.get_text(" ", strip=True) if autores_tag else None
paginas = paginas_tag.get_text(strip=True).replace("págs.", "").strip() if paginas_tag else None
results.append({
"año": year,
"volumen": volume,
"título": titulo,
"autores": autores,
"páginas": paginas,
"ejemplar_url": url
})
time.sleep(random.uniform(1, 3)) # espera entre artículos
except Exception as e:
print(f"⚠️ Error procesando {url}: {e}")
time.sleep(random.uniform(20, 30)) # espera larga tras error
time.sleep(random.uniform(20, 40)) # espera entre páginas
driver.quit()
# GUARDAR EN JSON
with open("dialnet_INV_y_ciencia_.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
print(f"✅ Finalizado. Se han extraído {len(results)} artículos.")
Una vez obtenido el JSON que tiene esta estructura:
[... {
"año": "1991",
"volumen": "183",
"título": "Origen de los asteroides",
"autores": "Richard P. Binzel , M. Antonietta Barucci ,
Marcello Fulchignoni",
"páginas": "66-73",
"ejemplar_url":
"https://dialnet.unirioja.es/ejemplar/27233"
},...]
se usa un script en Python para crear los enlaces de visualización
directa del artículo en Archive.org.El formato de dichos enlaces es:
https://archive.org/details (común a todos)
/iyc-1991/ (año)
IYC183-1991-12-dic/ (volumen, año y fecha)
page/14 (página)
/mode/1up?view=theater (común a todos)
Es necesario dar a cada elemento del json una URL al enlace de
archive.org. Se automatiza la creacion del enlace con este script. Para
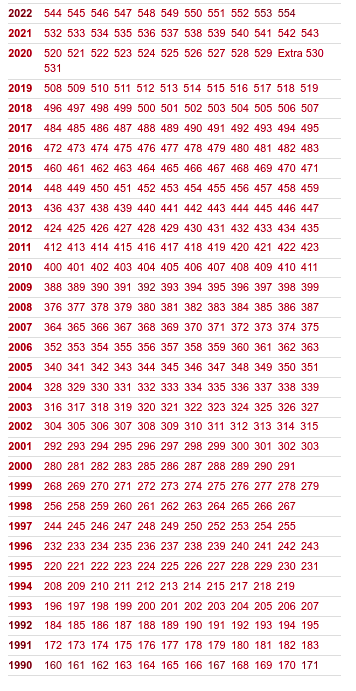
construir la URL, asocia cada número de volumen a un mes del año de forma
cíclica (dado que cada volumen va de enero a diciembre), comenzando en
enero para el volumen 160 y siguiendo la cadencia de volúmenes
de esta tabla:
Extrae el año, el volumen y la página de inicio del artículo para
completar la estructura del enlace.
Los meses en los que no se publica volumen deben tenerse en cuenta para
que no se le asigne una URL equivocada al siguiente volumen. Para ello,
intercalé en esos casos un elemento de json vacio.
{
"año": "1111",
"volumen": "1111",
"título": "",
"autores": "",
"páginas": "",
"ejemplar_url": "",
}
import json
# Lista cíclica de meses con su número
meses = [
"01-ene", "02-feb", "03-mar", "04-abr", "05-may", "06-jun",
"07-jul", "08-ago", "09-set", "10-oct", "11-nov", "12-dic"
]
# Volumen base para enero
volumen_base = 160
# Cargar el JSON original
with open("1.json", "r", encoding="utf-8") as f:
articulos = json.load(f)
# Añadir campo URL a cada artículo
for articulo in articulos:
año = articulo["año"]
volumen = int(articulo["volumen"])
pagina_inicio = articulo["páginas"].split("-")[0].strip()
# Calcular mes correspondiente al volumen
mes_index = (volumen - volumen_base) % 12
mes = meses[mes_index]
# Construir URL
url = f"https://archive.org/details/iyc{año}/IYC{volumen}-{año}-{mes}/page/{pagina_inicio}/mode/1up?view=theater"
articulo["url"] = url
# Guardar resultado en nuevo archivo
with open("con_url.json", "w", encoding="utf-8") as f:
json.dump(articulos, f, indent=2, ensure_ascii=False)
print("✅ URLs añadidas correctamente según volumen → mes.")
Lo realicé adjuntando al ChatGPT el archivo json con este prompt:
"Añade un campo de tema: en cada entrada de este json para cada
titulo. quiero que elijas entre estos temas:
Matemáticas
Medicina
Astronomía
Tecnología
Zoología
Botánica
Mecánica cuántica
Antropología
Física
Economia
Química
Biología
Genética
Neurociencia
Psicología
Ecología
Informática / Inteligencia Artificial
Arqueología
Historia
Geología
Climatología / Cambio climático
Filosofía de la ciencia
Ingeniería / Energía
Microbiologia
Bioquímica
Juegos
Paleontología
Evolución
Con el json terminado se configuró el buscador.